Histotalk
Talk to History. Literally.

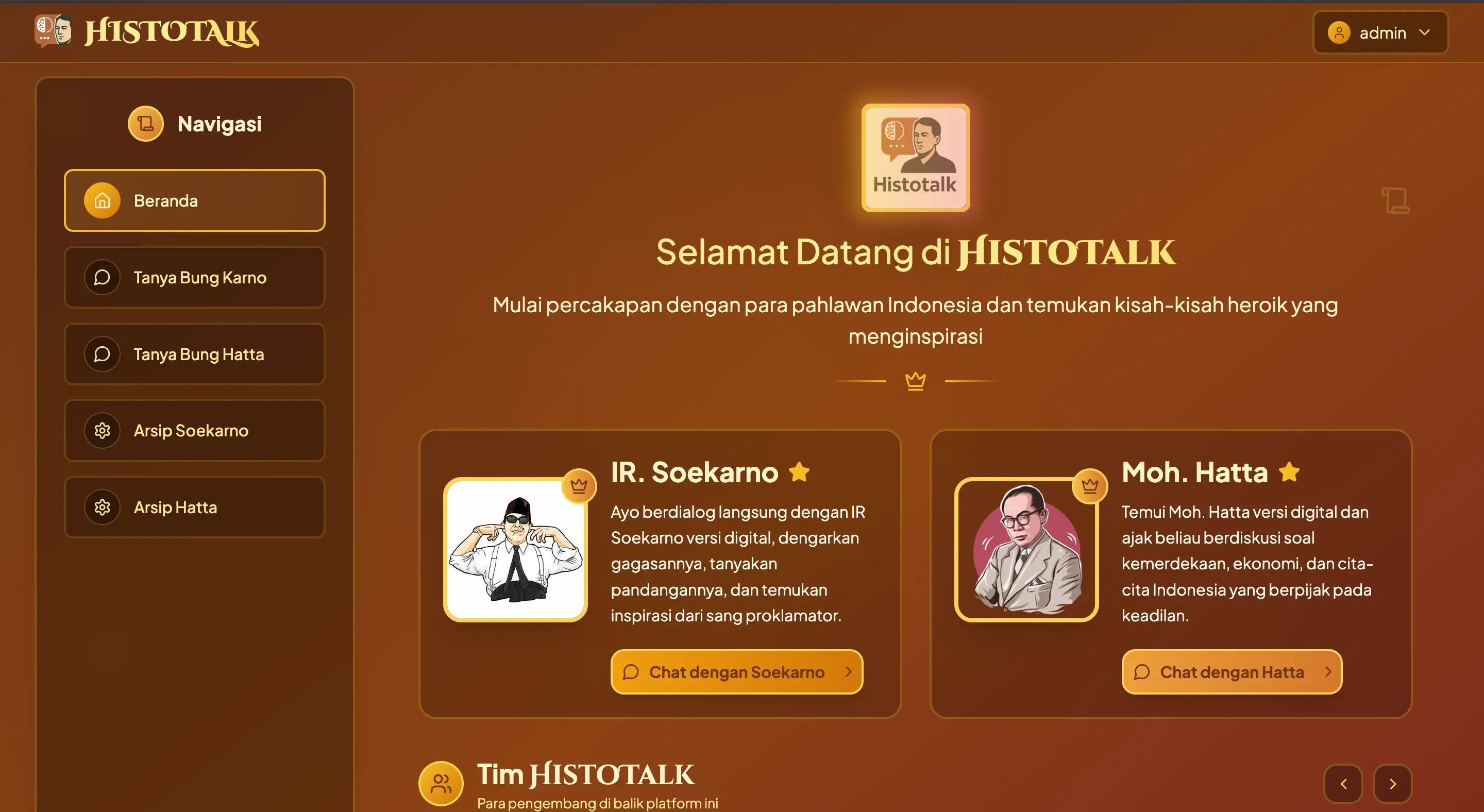
Histotalk is an interactive, AI-powered digital history museum where users can chat directly with historical figures. Instead of passively reading timelines and textbooks, users experience history through conversations — designed for curious, digital-native learners who prefer interaction over memorization.
Tech Stack
Understanding the Problem
Let's be honest — history education is often delivered in the least engaging way possible. Most students experience history as long texts, static timelines, and one-way explanations. This makes it hard to stay engaged, build emotional connection, or explore historical context beyond surface-level facts. History becomes something to memorize, not understand. As part of a capstone project with the theme of Education & Inclusivity, our team of 6 (3 ML engineers, 3 Frontend/Backend developers) set out to change this.
My responsibility was to work as a Frontend & Backend Developer with key objectives: Design and implement the frontend architecture with smooth conversational UX, build the backend API layer for handling auth, persistence, and AI integration, integrate the dual-AI system ensuring seamless switching between offline TensorFlow.js and cloud-based RAG, and bridge the gap between ML logic and real user experience.
How I Solved It
A systematic approach to building a production-ready platform.

Dual-AI Architecture
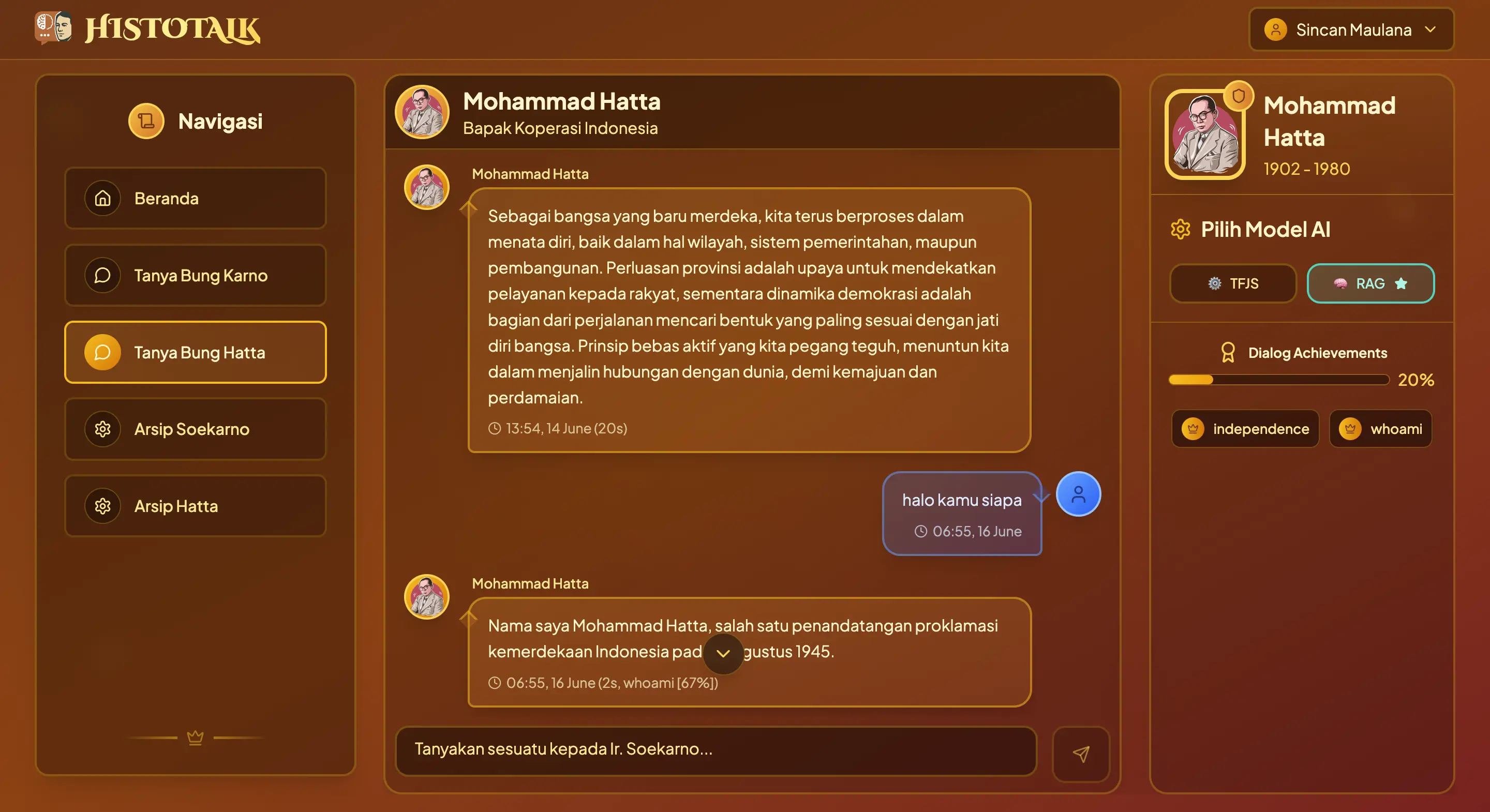
Histotalk uses a dual-AI architecture: TensorFlow.js runs in-browser for instant, offline-first responses, while RAG with Gemini 2.0 Flash handles deeper queries. The switch is based on confidence score — fast when possible, smart when needed.
Frontend Architecture
Built with React 19 + Vite, TypeScript, and Tailwind CSS. Features typing indicators, smooth transitions, prompt suggestions, and full mobile support. Uses Zustand for state management and implemented as a Progressive Web App (PWA).
Backend & API Layer
Developed using Node.js and Hapi.js with TypeScript. Handles authentication via Supabase and JWT, data persistence, logging with Winston, and routes requests to the appropriate AI layer. Deployed on Vercel.
Historical Accuracy
To prevent hallucinated history, data was manually curated from trusted sources. Built a structured ETL pipeline for retraining and an admin-only CRUD system to control knowledge updates, keeping responses factual and character-accurate.
Seamless AI Integration
Bridged ML logic with real UX — TensorFlow.js for instant browser inference, Flask + Cloud Run for RAG when needed. The modular architecture allowed the 6-person team to develop frontend, backend, and ML in parallel.
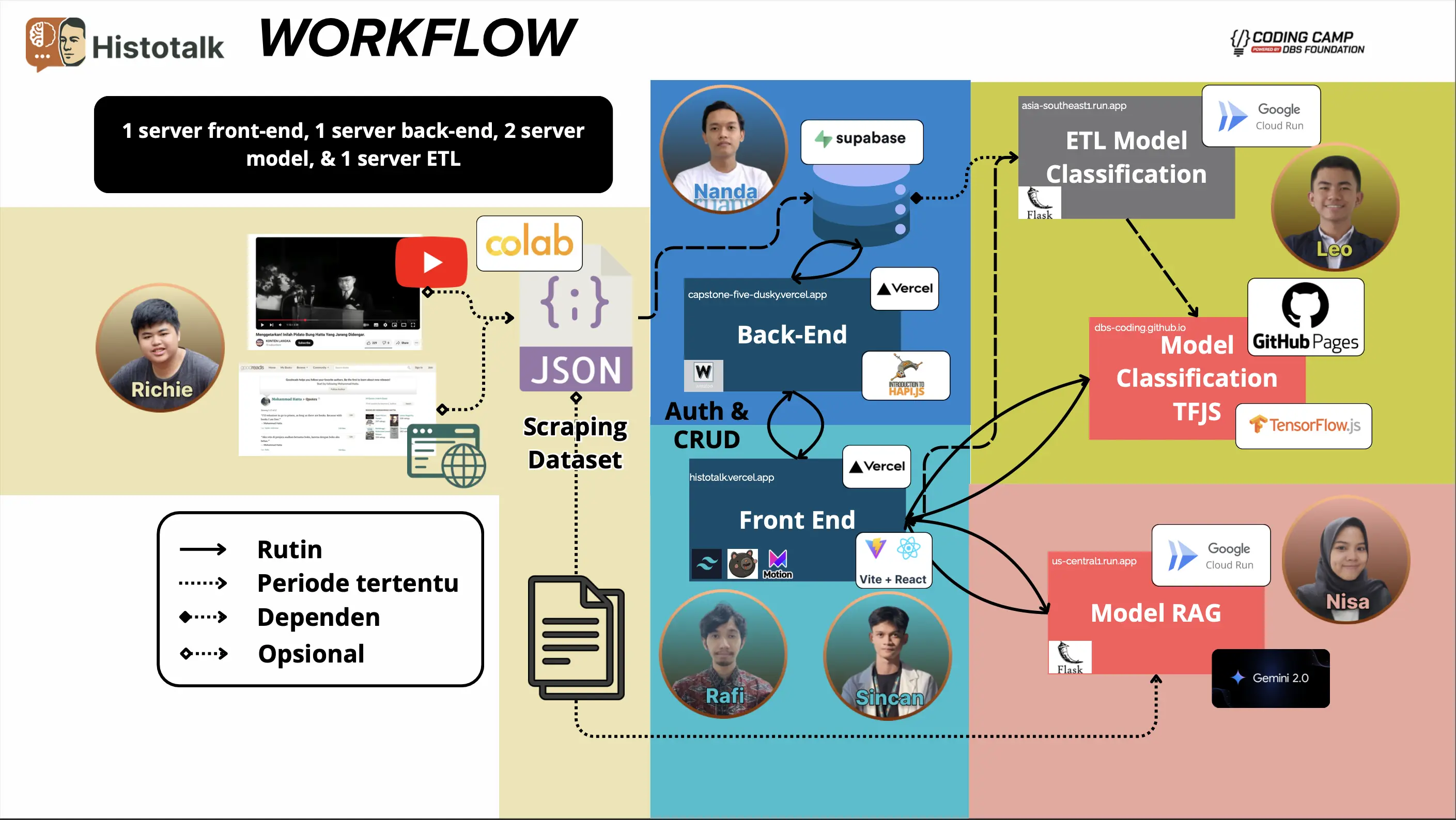
How It Works
Histotalk is built with a modular, production-style workflow: data is curated and processed through an ETL pipeline, the frontend handles fast user interaction and on-device AI inference, and the backend orchestrates authentication, data flow, and AI routing.
Most conversations are handled instantly using TensorFlow.js in the browser, while complex queries automatically fall back to a cloud-based RAG model powered by Gemini. This dual-model strategy keeps the system fast, accurate, and cost-efficient, while allowing each service to scale independently.
A Closer Look at the Experience
Explore the interface and system architecture that powers Histotalk.